










DVC(Data Version Control)是Mindeeo公司开发的一个开源工具,它将数据版本控制的概念引入了机器学习和数据分析领域。简而言之,DVC允许用户跟踪和管理大型文件(如数据集、模型权重和生成图像等),这些文件通常是传统版本控制系统(如Git)难以高效处理的。
以下是关于DVC软件的一些关键点:
目的:DVC旨在解决在协作环境中处理大数据时所面临的问题,包括数据的共享、追踪和重现性。通过集成到现有的工作流程中,DVC可以简化团队成员之间的沟通并确保每个步骤的可重复性。
特点:
- 数据追踪:DVC能够追踪数据的元信息及其相关参数,这使得在不同时间点和不同环境之间迁移项目变得更加容易。
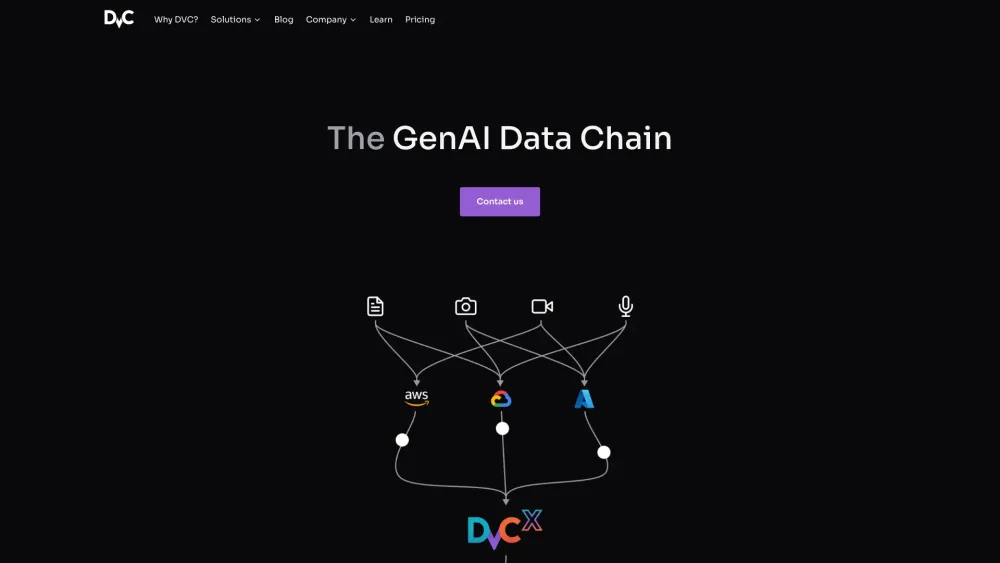
- 远程存储支持:DVC与云存储服务(如Amazon S3, Google Cloud Storage或HDFS)集成,允许用户从任何地方访问他们的数据。
- 模型管理:DVC可以用来管理和比较不同的模型配置和性能指标,这对于优化模型训练过程非常有用。
可扩展性:由于其轻量级的设计,DVC可以在本地运行,也可以扩展到分布式计算环境,例如Google Colab, AWS Sagemaker或者Kubeflow Pipelines。
工作原理:DVC使用一个独立的
.dvc文件系统来描述项目中所有的大型文件之间的关系和依赖。这个文件系统独立于实际的数据和模型文件,因此不会增加它们的体积。在实际操作中,用户会创建一个.dvc文件来关联一个特定的数据集或模型,然后DVC会负责维护该文件的元信息和指向真实数据位置的链接。命令行界面:DVC的主要接口是一个强大的命令行工具,提供了许多实用的命令,比如:
dvc init: 在项目中初始化一个新的DVC仓库。dvc add: 将新文件添加到DVC的管理范围中。dvc run: 运行一个实验或脚本的命令,同时记录输出到DVC系统中。dvc repro: 根据DVC文件中的指令重新执行整个流水线。dvc push/pull: 将数据推送到或从远程存储库拉取数据。生态系统:DVC不仅限于Python生态圈,还与其他流行的语言和技术栈兼容,如Rust, Go, Java等。此外,DVC社区提供了一系列插件和服务,进一步增强了它的功能和易用性。
适用场景:DVC适合用于以下场景:
- 需要频繁分享和更新大型数据集的项目。
- 对模型训练进行迭代和优化的机器学习任务。
需要在不同环境下保持一致性的数据分析工作流。
优势:
- DVC提供了一种标准的方法来组织和管理数据科学项目,提高了工作效率和可复现性。
- 通过集中式存储解决方案,如GitHub Actions, GitLab CI/CD or Azure Pipelines,DVC可以帮助自动化数据预处理、模型训练和评估的过程。
无论是在个人笔记本电脑上还是在云端的高性能计算集群中,DVC都能无缝地工作。
劣势:
- 对于初学者来说,掌握DVC的全部特性可能需要一定的时间和学习曲线。
如果项目的复杂程度不高,使用DVC可能会显得有些多余。
总结:总的来说,DVC是一种强大且灵活的工具,它在数据科学和人工智能领域的应用越来越广泛。无论是小型研究项目还是大规模企业部署,DVC都能够帮助提高效率、减少错误并促进团队合作。随着不断的发展和社区的壮大,DVC将继续为数据驱动型工作的未来奠定坚实的基础。